# node在常见场景中
- I/O密集型:因为他使用事件循环的处理能力,而不是启动一个线程为每一个请求服务,资源占用极少
- cpu密集型:由于单线程的原因,如果长时间运行计算,比如大循环,将会导致cpu实践篇不能释放,是的或许I/O无法发起。但适当调整和分解大型运算任务为多个小人物,是运算能够适时释放,不堵塞I/O调用的发起,这样既可以享受到并行一步I/O的好处,又可以充分利用CPU
# cpu密集型
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。
比如说要计算1+2+3+…+ 1亿、计算圆周率后几十位、数据分析。 都是属于CPU密集型程序。
此类程序运行的过程中,CPU占用率一般都很高。
假如在单核CPU情况下,线程池有6个线程,但是由于是单核CPU,所以同一时间只能运行一个线程,考虑到线程之间还有上下文切换的时间消耗,还不如单个线程执行高效。
所以!!!单核CPU处理CPU密集型程序,就不要使用多线程了。
假如是6个核心的CPU,理论上运行速度可以提升6倍。每个线程都有 CPU 来运行,并不会发生等待 CPU 时间片的情况,也没有线程切换的开销。
所以!!!多核CPU处理CPU密集型程序才合适,而且中间可能没有线程的上下文切换(一个核心处理一个线程)。
简单的说,就是需要CPU疯狂的计算。
# IO密集型
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,但CPU的使用率不高。
所以用脚本语言像python去做I/O密集型操作,效率就很快。
简单的说,就是需要大量的输入输出,不如读文件、写文件、传输文件、网络请求。
# node模块
node核心模块在node源代码的编译过程中,编译进了二进制执行文件。node在启动时,部分核心模块直接加载进了内存中,他们的加载速度极快
node对引入的模块进行缓存,减少二次引用时的开销。不同于浏览器缓存文件,node缓存的是编译和执行后的对象。
# node中引入模块经历
路径分析:如果不是核心模块,node会从当前目录的node_modules开始,逐渐向上级查找
文件定位:
- 分析文件拓展名:在标识符中不存在文件拓展时,node会按照js、node、jsoin的顺序补足拓展名依次尝试。(他调用fs模块同步堵塞式检测,所以如果时node和json文件,直接写入require中可以提升性能)
- 分析目录和包:如果按照路径找到的不是一个文件,而是目录,则会当成包来处理。从package.json中找到main属性进行定位引入,如果失败,则会将index作为默认文件名
编译执行:定位到具体文件后,node会根据路径载入并且编译。
- js文件:用过fs模块同步读取文件后执行编译。(下面细说)
- node文件:这是用C/C++编写的拓展文件,通过dlopen方法加载最后编译生成的文件。
- json文件:通过fs同步读取后,使用JSON.parse解析。
- 其他文件:当成js文件载入
// 每个文件模块都是一个对象 function Module(id, parent){ this.id = id this.exports = {} this.parent = parent if(parent && parent.children) { parent.children.push(this) } this.filename = null this.loaded = false this.children = [] }
通过require.extensions['.ext']的方式自定义特殊拓展名的加载
# 编译执行js文件
文件在编译之后会变成这样
(function (exports, require, module, __filename, __dirname){
// 文件中的代码
})()
包装后的代码通过vm原生模块的runInThisContext方法执行,返回一个具体的function对象如上。在执行后,模块的exports属性被返回给了调用方,exports属性上的任何方法和属性都可以被外部调用。
exports是以形参的方式传入,直接赋值会改变其的引用,而步伐改变作用域的值。
# 异步I/O
# 系统的堵塞I/O与其异步I/O的实现
计算机有堵塞与非堵塞I/O。
堵塞I/O例如读取文件,他会经历完成磁盘寻道、读取数据、赋值数据到内存中,完成全部操作后,本次操作才算执行完成。堵塞I/O导致cpu等待I/O,浪费等待时间。为了提高性能,内核提供了非堵塞I/O。
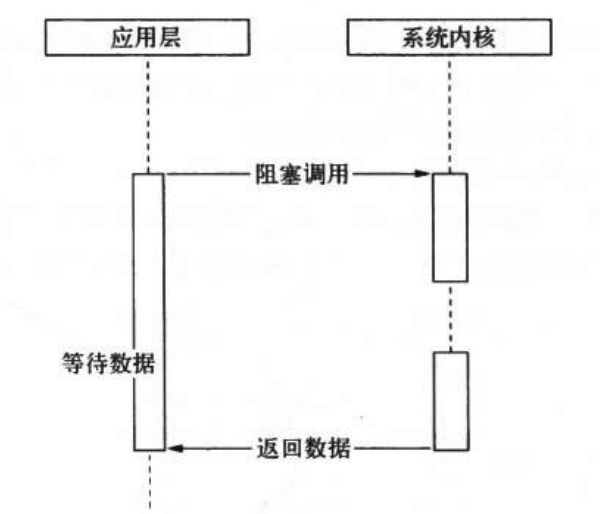
应用程序需要非堵塞I/O时,先打开文件描述符(类似于应用程序与内核之间的凭证),然后根据文件描述符去实现文件数据的读写。这样,在应用程序发出调用信号后,内核可以立即返回,但不懈怠数据,想要获取数据,还需要通过文件描述符在此读取。
如何再一次获取结果数据,可以通过轮训去向内核查询。
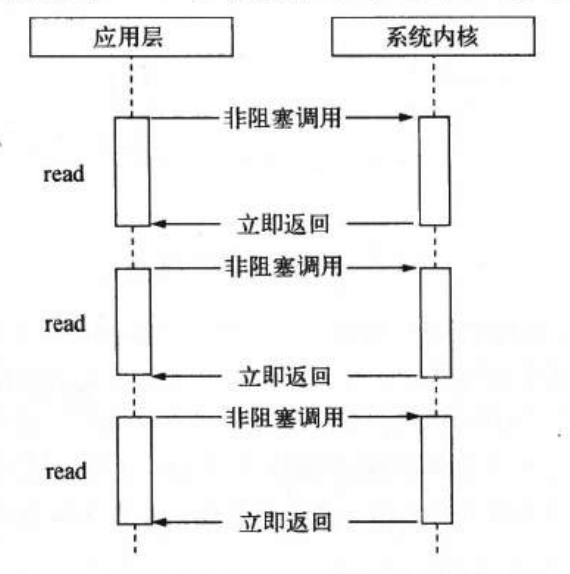
轮训技术满足了非堵塞I/O确保完整数据的需求,但对于应用程序而言,他仍然只能算是一种同步。因为应用程序仍然需要等待I/O完全返回。我们希望,在内核执行完成后,能够发信号给应用,同时返回数据,应用拿到数据后,执行回调。
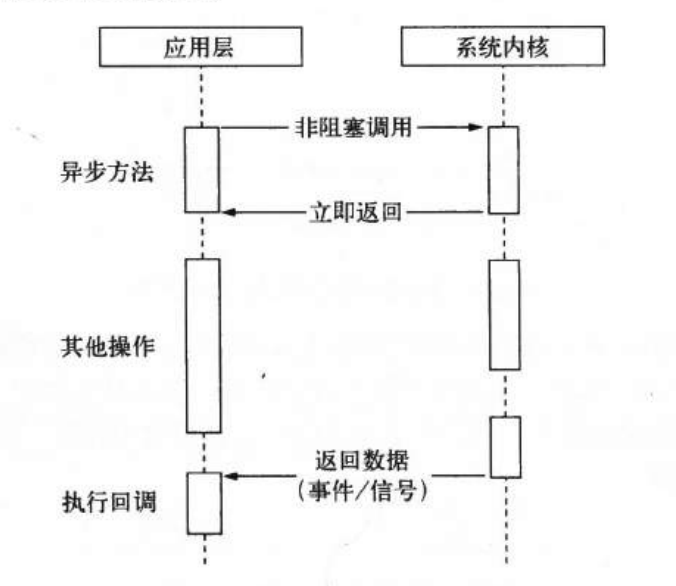
要实现这种异步I/O,我们可以让子线程去进行堵塞I/O活非堵塞I/O加轮训的过程,通过线程之间的通信就可以完成计算处理。

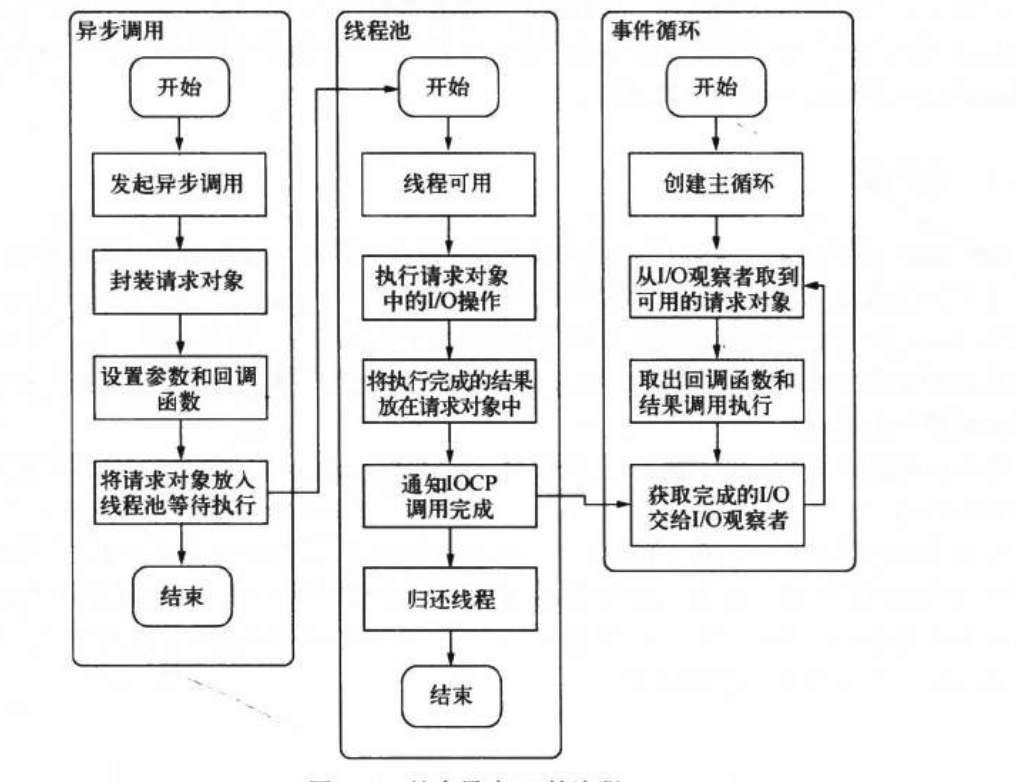
在*nix下,node自行实现了线程池完成了异步I/O的实现。而在window下异步I/O方案则是IOCP。它某种程度上提供了理想的异步I/O,尽管实质上仍然是线程池去实现的,但是他的线程池由内核管理。
为了兼容windows平台与*nix的差异,node提供了libuv作为抽象层封装,所有平台兼容性的判断由他完成。
# nodejs的异步I/O
在node进程启动后,node便会创建一个类似while(true)的循环,每一次循环的过程叫做Tick。每个Tick的流程如下:
- 判断是否有事件要处理,没有直接退出
- 如果有,取出一个事件,判断是否有关联回调
- 如果有,执行回调
- 返回步骤一
【判断是否有事件要处理】通过询问观察者来完成。每个事件循环可能有一个或多个观察者。这些事件可能来自网络请求、文件I/O等,他们便分别对应网络I/O观察者、文件I/O观察者。
在window下,这个循环由IOCP创建,*nix下基于多线程创建。
整体流程如下
# 非I/O的异步
# setTimeout
调用setTimeout或者setinterval创建的定时器会被插入到定时器观察者内部的红黑树中。每次执行Tick时,会从该红黑树中迭代去处定时器对象,检查是否超时,如果超时,形成一个事件,他的回调函数会立刻被执行。(所以定时器并没精确)
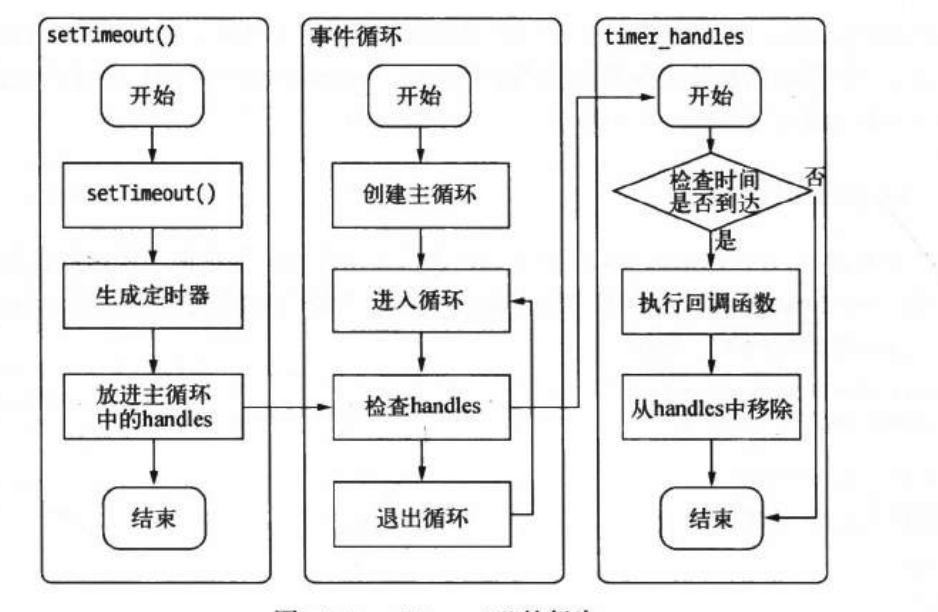
# process.nextTick
每次调用process.nextTick方法,只会将回调函数放入队列中,在下一轮的tick时取出执行。所以他比setTimeout(fn, 0)更轻量,性能更好
# setImmediate
他与process.nextTick都是讲回调函数延迟执行,但他的优先级并没有process.nextTick高。因为process.nextTick属于idle观察者,setImmediate是属于check观察者。在每一轮循环检查中,idle观察者先于I/O观察者,I/O观察者先于check观察者。
且process.nextTick回调保存在数组中,setImmediate保存在链表中。process.nextTick在每一轮循环中会讲数组中全部函数执行完,setImmediate则每轮执行一个。
# 异步并发的控制
在node中调用
for(let i=0; i<100; i++) {
async()
}
我们可以轻松异步发起一百次异步调用,但是如果并发量过大,下层服务器会吃不消,如果是对文件系统操作,操作系统的文件描述符的数量会被瞬间用光,此时会抛出错误。所以,需要进行一些防控。
# bagpipe
实现一个任务队列控制并发量,如果当前活跃(发起但为执行回调)的异步调用量小于限定值,从队列中取出执行
const bagpipe = new Bagpipe(10) // 并发量10
for(let i=0; i<100; i++) {
bagpipe.push(async ,callback)
}
# async
async.parallelLimit([
fn1,
fn2,
], 10, callback)
# 内存控制
# 垃圾回收与内存限制
# 对象分配
当我们在代码中声明变量并赋值,对象的内存就分配在堆中,如果已申请内存的空闲内存不够的话,将继续申请,直至到达v8的限制。
在64位系统的情况下,最大约1.4G
以1.5G的垃圾回收为例,v8做一次小的垃圾回收大概需要50ms以上,而非推进式垃圾回收至少需要1s以上,垃圾回收时js执行线程会被暂停(全停顿)。这样,应用的性能和响应能力会大受影响。
当然,我们可以自行改变这个限制
node --max-old-space-size=1700 main.js ## 单位MB 设置老生代内存
node --max-new-space-size=1024 main.js ## 单位KB 设置新生代内存
# 垃圾回收
v8的垃圾回收策略基于分代式垃圾回收机制。他按照对象的存活时间进行分代,然后对不同分代的内存分别进行高效回收。
v8中分为新生代和老生代,他们存储存活时间较短的内存和存活时间长、常驻内存。64位系统中,老生代大概1400MB新生代大概32MB
新生代使用scavenge算法
scavenge算法的实现主要采用了cheney算法,他将内存一分为二,每一部分叫semispace。他们一个处于使用中,叫form区,一个叫to区。分配内存时只使用form
| 新生代 | |__________|___________| | form | to |当进行垃圾回收时,将检测form中所有对象,将存活对象赋值到to区,非存活删除,然后将to区作为新的form区,form区作为新的to区
在将form区对象赋值到to区时,会检测每个对象,当符合条件(存活时间过长)时,它将晋升到老生代。
上面所说的条件有二,1、如果他经历过一次scavenge回收了,则符合。 2、如果此时to区的空间占用以超过25%则直接晋升
老生代使用Mark-Sweep 和Mark-Compact相结合
Mark-Sweep包括标记和清除两个阶段。标记阶段会遍历堆中的对象,标记活着的对象,清除阶段会清除未标记的对象。
Mark-Sweep完成清理后,会在内存中出现很多内存片段。
Mark-Compact相比Mark-Sweep,在整理的时候将标记死亡的内存向一侧移动,整理完毕后,直接清理边界内存
v8主要使用Mark-Sweep,当当前内存不足以支持从新生代晋升过来的对象时,使用Mark-Sweep清理。
为降低全堆垃圾回收到对js执行带来的停顿问题,v8从标记入手,原来一口气做完的标记改为增量标记,拆分成很多小“步进”,没标记完一“步进”,执行一会js。
# 内存的使用
process.memoryUsage()
// 输出
{
rss: 13902819, // 进程的常驻内存 进程内存包括rss、交换区、文件系统
heapTotal: 7195904, // v8申请到的内存
heapUsed: 2821496, // 已使用的内存
}
os.totalmem() // 系统总内存
os.freemem() // 系统空闲内存
通过process.memoryUsage输出出来的数据发现,v8申请的内存总量会小于进程的常驻内存,所以node的内存并不都是v8分配的,而这些不是v8分配的内存叫做堆外内存。例如创建buffer的时候,将不会或很少增加heapTotal,heapUsed,但rss却会大量增加。
# 内存泄漏
内存泄漏的实质就是应该回收的对象没有回收,常驻在了老生代中。
常见原因:
- 缓存
- 队列消费不及时
- 作用域未释放
案例一:
我们自己实现的缓存通常是通过键值对进行存储的
const ache = {}
function get(key) {
if ache[key] return ache[key]
else // action
}
function set(key, value) {
ache[key] = value
}
这时随着存时间增长,该对象将越来越大,会造成内存过大。一个简单的方式是去添加一个limit变量,去限制ache的数量,从而控制它的大小确保不会变得不可控。也可以使用LRU算法去实现缓存。
案例二:
模块在编译后会形成局部作用域,因为模块有缓存,所以不被释放,所以模块属于常驻老生代。模块的设计至关重要
const arr = []
exports.leak = () => {
arr.push(Math.random())
}
与案例一同理,如果这样的设计很有必要,那么需要设计相对应的清理arr的方法。
# 大内存
在操作大文件的时候,无法通过fs.redFile和fs.writeFile直接进行大文件的操作,而改用fs.createReadStream和fs.createWriteStream方法通过流的方式实现对大文件的操作。
const reader = fs.createReadStream('in.txt')
const writer = fs.createWriteStream('out.txt')
reader.on('data', chunk => {
writer.write(chunk)
})
reader.on('end', () => {
writer.end()
})
// 另一种写法
const reader = fs.createReadStream('in.txt')
const writer = fs.createWriteStream('out.txt')
reader.pipe(writer)
通过流,将不会受到v8内存限制的影响。
# Buffer
buffer是js和c++结合的模块,他将性能相关部分用c++实现,非性能部分用js实现。
node在进程启动时就已经加载了buffer将它放到全局对象上
buffer对象类似数组,他的元素为16进制的两位数,即0~255。
1字节等于8比特,即8个二进制数字组成,两个16进制数字
UTF-8编码中一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。
console.log(new Buffer('深入', 'utf-8'))
// <Buffer e6 b7 b1 e5 85 a5>
# buffer内存分配
buffer所占用的内存不是通过v8分配的,而是在c++层面申请的。因为处理大量的字节数据不能需要一点就想操作系统申请一点的方式,这可能造成大量的内存申请的系统调用,对操作系统有一定压力。
Node采用slab的动态内存管理机制。
slab就是一块提前申请好的固定大小的内存区域,他可能处于full、partial、empty三种状态。在Node中,每块slab为8KB。node将以它作为单位单元进行内存分配。
当创建一个小于8KB的值是,node按照小对象的方式进行分配,创建一个新的slab单元,使用其部分内存。当再次创建一个Buffer对象时,如果这个slab剩余空间充足,则使用剩余空间,如果不够,则再一次创建一个新的slab单元。
new Buffer(1)
new Buffer(1)
new Buffer(8891)
// 共使用两个slab单元
当创建一个大于8KB的值,会直接分配一个SlowBuffer对象作为slab单元,这个slab单元将会被这个大buffer对象独占。SlowBuffer是在C++中定义的。
# buffer的拼接
常见的buffer拼接
var rs = fs.createReadStream('test.md', {highWaterMak: 5})
var data = ''
rs.on("data", trunk => data+= trunk)
当输入流中有宽字节时,就会出现乱码的现象。
因为data += trunk隐藏了data.toString() += trunk.toString()的操作。
例如当出现汉字的时候,每个汉字占3个单位,当我们设置了每个buffer大小为5,第二个汉字实则没有完全传过来,此时进行toString默认以UTF-8进行编码,故成了乱码。
所以,我们需要将小Buffer对象拼接为一个Buffer对象,然后转码
const chunks = []
let size = 0
res.on("data", trunk => {
chunks.push(chunk)
size += chunk.length
})
res.on("end", () => {
const buf = Buffer.concat(chunks, size)
const str = iconv.deocde(buf, 'utf8')
})
# buffer性能
在网络I/O方面,buffer的传输会高于字符串的传输的性能
在文件I/O方面,文件读取时,设置highWaterMark对性能至关重要。fs.createReadStream的工作方式是在内存中准备一块Buffer,fs.read读取的时候逐步从磁盘将字节复制到Buffer上。完成一次读取,则从这个Buffer中通过slice方法取出部分作为一个小Buffer对象通过data事件传递给调用方。如果Buffer用完则重新分配一个,如果有剩余,则继续使用。highWaterMark设置过小,可能导致系统调用次数过多,highWaterMark的大小决定触发系统调用和data事件的次数。
# 网络编程
# TCP 传输控制协议
tcp属于七层模型中的传输层协议,很多应用层协议都基于tcp构建,如HTTP、SMTP、IMAP
tcp是面向连接的协议,传输之前需要三次握手,创建会话过程中,服务器端和客户端分别提供一个套接字,两个套接字共同形成一个连接。
创建tcp服务器:通过net.createServer(listener)创建一个tcp服务器,listener是连接connection的侦听器
const net = require("net")
const server = net.createServer((socket) => {
socket.on("data", function (data) {
console.log(data.toString())
socket.write("hello\n")
})
socket.on("end", function (data) {
console.log("断开\n")
})
socket.write("欢迎\n")
})
server.listen(8080, function(){
console.log("server bound\n")
})
// 另一种方式
const server = net.createServer()
server.on('conncetion', function(socket) {
//
})
serve.listen(8080)
创建tcp客户端
const net = require("net")
const client = net.connect({port: 8080}, function(){
console.log("client connected")
client.write("hi\n")
})
client.on("data", function(data){
console.log(data.toString())
client.end()
})
client.on("end", function(){
console.log("client disconnected\n")
})
执行后
// 服务终端
server bound
hi
断开
// 客户终端
client connected
欢迎
hello
client disconnected
由于TCP套接字是可写可读的stream对象,可以利用pipe方法实现管道操作
// echo服务器
const server = net.createServer((socket) => {
socket.write("Echo server")
socket.pipe(socket)
})
server.listen(1337, '127.0.0.1')
如果网络中频繁出现小数据包,例如每次只发一个字节的内容,将十分浪费网络资源。Nagle算法将要求缓存区的数据达到一定数量或者一定时间后再将其发出,小数据包会被Nagle算法合并。Node中,TCP默认启用Nagle算法,调用socket.setNoDelay(true)可关闭Nagle,将write的内容立刻发到网络中。
# UDP 用户数据包协议
与TCP不同的是,UDP中,一个套接字可以与多个UDP服务通信,面向事务提供简单不可靠传输服务。
UDP套接字创建后即可作为客户端也可作为服务端。
// 创建套接字
const dgram = require("dgram")
const socket = dgram.createSocket("udp4")
// 服务端
const dgram = require("dgram")
const server = dgram.createSocket("udp4")
server.on("message", (msg, rinfo) => {
console.log(`${rinfo.address}:${rinfo.port} --- ${msg}`)
})
server.on("listening", (msg, rinfo) => {
console.log("ok")
})
server.bind(8080)
// 客户端
const dgram = require("dgram")
const client = dgram.createSocket("udp4")
const message = new Buffer("一些信息")
client.send(message, 0, message.length, 8080, "localhost", (err, bytes) => {
client.close()
})
# HTTP
超文本传输协议
const http = require("http")
http
.createServer((req,res) => {
res.writeHead(200, {'Content-Type': 'text/plain'})
res.end("end")
})
.listen(8080, 'localhost')
从协议的角度来说,现在的应用,如浏览器,其实是一个HTTP的代理,用户的行为将会通过它转化为HTTP请求报文发送到服务端,服务端处理后,发送响应报文给代理,代理在解析报文后,将用户需要的内容呈现在界面上。
在node中,http服务继承自TCP服务器(net模块),它能与多个客户端保持连接,由于其采用事件驱动的形式,并不为每一个连接创建额外的线程或进程,保持很低的内存占用,所以能实现高并发。
tcp与http的区别在于开启keepalive后,一个tcp会话可以用于多次请求和响应。在创建一个connection后,可能会有多次request。tcp服务以connection为单位进行服务,http以request为单位进行服务。
http模块将连接所用的套接字的读写抽象为serverRequest和serverResponse对象。
对于TCP的读操作,http将其封装为serverRequest对象。http模块在接收到报文后,报文头部通过http_parser进行解析。报文体则是一个只读流对象,可以通过下面方式去收集
function(req, res){
const buffers = []
req
.on("data", (thunk) => {
buffers.push(thunk)
})
.on("end", () => {
const buffer = Buffer.concat(buffers)
})
}
http相应对象可以看成是一个可写的流对象。通过res.setHeader和res.writeHead方法去改变相应头。报文体则通过res.write和res.end方法实现,差别在于end会先调用wirte发送数据,然后发信号告知服务器本次响应结束。响应结束后,http服务器可能会将当前的连接用于下一次请求或关闭请求。
http模块提供http.request去构造客户端。
const http = require("http")
http.request({
hostname: "localhost",
post: "8080",
path: "/",
method: "GET"
}, (res) => {
res.setEncoding("utf8")
res.on("data", (chunk) => {
console.log(chunk)
})
})
http提供的ClientRequest对象也是基于TCP实现的,在一个keepalive的情况下,一个底层连接可以多次用于请求。为了重用TCP连接,http模块包含一个默认的客户端代理对象http.globalAgent,他对每个服务器端创建的连接进行了管理,默认情况,ClientRequest对象对同一个服务器发起的http请求最多创建五个连接。也就是说,同时对一个服务器发起十次http请求实质上只有吴哥请求处于并发状态,后续请求需要等待某个请求服务完成后才真正发出。可以手动更改这一限制
const agent = new http.Agent({ maxSocket: 10 })
const options = {
hostname: "localhost",
post: "8080",
path: "/",
method: "GET",
agent,
}
# websocket
websocket客户端基于事件编程模型与node中自定义事件几乎相差无几
websocket实现了客户端与服务器之间的长连接,而node事件驱动的方式十分擅长于大量的客户端保持高并发连接
websocket作为h5的重要特性以形成RFC6455规范,他在浏览器中如下使用
// 与服务器创建websocket协议请求,每50ms向服务器发送一次数据,同时通过onmessage接受服务器传来的数据,故他相比http可以双向通信
const socket = new WebSocket("ws://localhost:8080/test")
socket.onopen = () => {
setInterval(function() {
if(socket.bufferedAmount === 0) socketsend(getUpdateData())
}, 50)
}
socket,onmessage = (event) => {
// TODO
}
# websocket握手
客户端创建连接的时候,通过http发送请求报文,其中包括以下协议头(部分)
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: BBKDABDKUWFA==
Sec-WebSocket-Key为随机生成的base64编码,服务端收到后,与指定字符相连,通过sha1安全散列算法计算出结果后,在进行base64编码,返回给客户端,响应头
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: andjJADAJDAJD==
客户端校验Sec-WebSocket-Accept,如果成功开始接下来的数据传输
# websocket数据传输
握手完成后,不在进行http交互,而开始websocket的数据帧协议。
当调用send发送一条数据时,协议可能将它封装为一帧或者多帧数据然后逐帧发送。
为了安全考虑,客户端需要对发送的数据进行掩码处理,服务器一旦接受到无掩码帧,连接将关闭。服务端发送客户端则无需掩码,如果客户端收到了带掩码的数据帧,连接将关闭。
# 网络服务与安全
node在网络安全上提供了crypto、tls、https三个模块
# TLS/SSL
TLS/SSL是一个公钥/私钥结构。
客户端与服务器都有自己的公私钥,建立连接前,他们交换公钥,发送数据的时候,用对方的公钥加密并发送给对方。
node底层用openssl实现的TLS/SSL。
为了解决中间人攻击,TLS/SSL引入了数字证书。
对客户端扮演服务器,对服务器扮演客户端,以骗取双方密钥
数字证书中包含了服务器的名称、主机名、服务器公钥、签名办法机构等,在建立连接前会通过证书中的签名确定收到的公钥来自服务器。
CA(数字证书认证中心),他负责为站点颁发证书,证书中有CA通过自己的公钥私钥实现的签名。服务器需要通过自己的私钥生成CSR(证书签名请求)文件,CA机构通过这个文件颁发属于该服务器的证书。
# TLS服务
通过tls创建安全的TCP服务
// echo
const tls = require('tls')
const fs = require('fs')
tls.createServer({
key: fs.readFileSync('./keys/server.key'),
cert: fs.readFileSync('./keys/server.crt'),
requestCert: true,
ca: [fs.readFileSync('./keys/ca.crt')]
},(stream) => {
stream.setEncoding('utf8')
stream.pipe(stream)
}).listen(8080)
tls也提供了connect方法构建客户端。
const tls = require('tls')
const fs = require('fs')
const stream = tls.connect(8080, {
key: fs.readFileSync('./keys/server.key'),
cert: fs.readFileSync('./keys/server.crt'),
ca: [fs.readFileSync('./keys/ca.crt')]
}, () => {
process.srdin.pipe(stream)
})
stream.setEncoding('utf8')
stream.on("data", (data) => {
//
})
stream.on("end", () => stream.close())
# https
https就是工作在tls/ssl上的http。
// 服务端
const https = require('https')
const fs = require('fs')
https.createServer({
key: fs.readFileSync('./keys/server.key'),
cert: fs.readFileSync('./keys/server.crt'),
}, (req,res) => {
res.end("hello")
}).listen(8080)
// 客户端
const https = require('https')
const fs = require('fs')
const option = {
hostname: "localhost",
post: "8080",
path: "/",
method: "GET",
key: fs.readFileSync('./keys/server.key'),
cert: fs.readFileSync('./keys/server.crt'),
ca: [fs.readFileSync('./keys/ca.crt')]
}
option.agent: new http.Agent(option)
const req = https.request(option, (res) => {
res.setEncoding("utf-8")
res.on("data", (d) => {
console.log(d)
})
})
req.end()
# web应用
req.method
url.parse(req.url).pathname ## /path
url.parse(req.url, true).query ## ?foo=bar&baz=val
# Cookie
解析cookie
req.cookie = parseCookie(req.headers.cookie)
function parseCookie(cookie){
const cookies = {}
if(!cookie) return cookies
const list = cookie.split(";")
for(let i = 0; i < list.length; i++){
const pair = list[i].split("=")
cookies[pair[0].trim()] = pair[1]
}
return cookies
}
设置cookie时
Set-Cookie: "name=value; Path=/; Expires=Sun, 23-Apr-23 09:01:35 GMT; Domain=.domain.com"
Expires和Max-Age是用来设置过期时间,如果不设置,则在浏览器关闭时失去cookie
HttpOnly设置浏览器无法通过document.cookie去更改cookie值
Secure为true时,仅在https中有效
如果域名的根结点有设置cookie,子节点都会带上它,会导致请求头过大,浪费资源。
例如过静态资源就不需要带上它,所以,可以将静态资源放在特殊的域名下。使用额外的域名还可以突破浏览器下载线程数量的限制
但是换额外域名意味着在将域名转为ip进行的dns查询需要执行不止一次,不过现在的浏览器会有dns缓存以削弱这个副作用
# session
cookie在前后端皆可修改,而session只保留在服务端。
服务器启用session后,约定一个键值(任意),再收到请求后,一旦服务器没有检测到该值,就会生成一个新的值让其携带
将每个客户和服务器中的数据一一对应有两种常见方式:
- 基于Cookie实现用户与数据的映射
- 基于查询字符实现用户与数据的映射
基于cookie查询
const sessions = {}
const key = "session_id"
const EXPIRES = 20 * 60 * 1000
function generate() {
const s = {}
s.id = (new Date()).getTime() + Math.random()
s.cookie = {
expire: (new Date()).getTime() + EXPIRES
}
sessions[s.id] = s
return s
}
// 当请求来的时候
function(req, res) {
const id = req.cookies[key]
if(!id){
req.session = generate()
} else {
const s = sessions[id]
if(s){
if(s.cookie.expire > (new Date()).getTime()) {
// 更新时间
s.cookie.expire = (new Date()).getTime() + EXPIRES
req.session = session
} else {
// 超时了
delete sessions[id]
req.session = generate()
}
} else {
req.session = generate()
}
}
handle(req, res)
}
// 后端更改了session 还需要响应客户端时重新setCookie,重写writeHead实现
writeHead = res.writeHead
res.writeHead = function() {
const cookies = res.getHeader('Set-Cookie')
const session = serialize('Set-Cookie', req.session.id)
cookies = Array.isArray(cookies) ? cookies.concat(session) : [cookies, session]
res.setHeader('Set-Cookie', cookies)
return writeHead.apply(this, argumant)
}
当cookie被禁用时,通过查询字符串实现,当请求路径中没有查询参数或者没有指定key,则通过重定向自行加入session_id,重新请求。
此处的sessions即为内存上的一块,当数据量变大,或者开启多线程时,数据可能无法共享,所以通常将session集中化,使用redis等缓存可实现。但连接这些缓存工具会出现网络请求,他有以下特征
- node与缓存服务保持长连接,而非频繁短链接,握手导致延迟至影响初始化
- 高速缓存直接在内存中进行数据存储和访问
- 缓存服务通常与node进程运行在相同机器或机房中,网速影响较小
session的口令存在客户端,那即会出现session的安全问题。为了防止伪造口令,可以将口令通过私钥加密进行签名。客户端没有私钥,很难伪造签名。服务端响应时需要将口令和签名进行对比,如果非法,将服务器端的数据立刻过期。
// 通过私钥签名
function sign(val, secret) {
return `${val}.${crypto.createHumc('sha256',secret).update(val).digest('base64').replace(/\=+$/,"")}`
}
// 检查签名
function unsign(req.sessionId, sercet) {
const str = val.slice(0, val.lastIndexOf('.'))
return sign(str, secret) === val ? str : false
}
这样攻击者不知道私钥,便无法伪造签名。但是如果攻击者获得了一个真实的口令和签名,他就能伪装身份。一种方案是将客户端的某些独有的信息与口令作为原值,然后签名,这样攻击者一旦不在原始的客户端上进行访问,就会导致签名失败,这些独有信息包括用户ip和用户代理。
# 缓存
缓存需要客户端与服务端共同支持。
将文件的内容生成散列值,携带进入响应头ETag,而浏览器收到之后,就会再下次请求时,将值放入If-None-Match请求头。服务端可以通过对比If-None-Match中的内容,与对应文件的内容散列值来确定是否需要传递新的内容。如果不需要,直接返回304
function(req,res){
fs.readFile(filename, function(err, file){
const hash = getHash(file)
const noneMath = req['if-none-match']
if(hash === noneMath) {
res.wirteHead(304, "Not Modified")
res.end()
} else {
res.setHeader("ETag", hash)
res.writeHead(200, "ok")
res.end(file)
}
})
}
function getHash(str) {
return crypto.createHash('sha1').update(str).digest('base64')
}
这样的方式,尽管不需要多次传递文件,但是每次仍然需要发请求确认文件是否过期,那么可以使用Expires或Cache-Control头。
// Expires
const expires = new Date()
expires.setTime(expires.getTime() + 10 * 365 * 24 * 60 * 1000)//十年
res.setHeader("Expires",expires.toUTCString())
// Cache-Control
res.setHeader("Cache-Control", "max-age=" + 10 * 365 * 24 * 60 * 1000)
Expires直接指定什么时候过期,但是服务器和浏览器的时间可能不同。
max-age会覆盖Expires的设置
如果想要清楚缓存,可以通过url中查询参数实现。http://url.com/?v=2111将版本或者hash作为查询参数,当参数不是最新时,使浏览器重新发起请求使得内容被更新。
# 上传数据
node帮我们解析请求头,但是其他数据需要我们自行解析
# 请求体
判断是否含有请求体
function hasBody(req){
return 'transfer-encoding' in req.headers || 'content-length' in req.headers
}
# 表单数据
function is(req){
return req.headers['content-type'] === 'application/x-www-form-urlencoded'
}
req.body = querystring.parse(req.raqBody)
# formdata
特殊表单(formdata)与普通表单区别在于formdata可以包含文件
function isFormdata(req){
return req.headers['content-type'] === 'multipart/form-data'
}
const formidable = require("formidable")
function(req, res) {
if(hasBody) {
if(isFormdata(req)){
const form = new formidable.IncomingForm()
form.parse(req, (err, fields, files) => {
req.body = fields
req.files = files
handle(req, res)
})
}
} else {
handle(req, res)
}
}
# 附件下载
const http = require('http')
const fs = require('fs')
const path = require('path')
http.createServer(function (req, res) {
function sendFile(filepath) {
fs.stat(filepath, function (err, stat) {
const stream = fs.createReadStream(filepath)
res.setHeader('Content-Type', 'text/plain')
res.setHeader('Content-Length', stat.size)
res.setHeader('Content-Disposition', 'attachment; filename="' + path.basename(filepath) + '"')
res.writeHead(200)
stream.pipe(res)
})
}
sendFile('test2.js')
}).listen(8080)
# 进程
# 事件驱动
Apache是采用多线程/多进程模型实现的,所以当并发增长到上万时,内存耗用的问题将会暴露出来。为此,事件驱动模型的服务出现,node与nginx都是基于事件驱动方式实现,采用单线程避免来不必要的内存开销和上下文切换开销。
但基于事件驱动还有两个主要问题 CPU利用率 和 进程健壮性。
# 多进程
由于所有处理都在单线程上进行,影响事件驱动服务模型性能的点在于CPU的计算能力,他决定了服务上限。所以解决多核CPU利用问题带来的提升是客观的。理想状态是每个进程各用一个CPU。
// master
const fork = require('child_process').fork
const cpus = require('os').cpus()
for(let i = 0; i < cpus.length; i++){
fork('./worker.js')
}
// worker
const http = require('http')
http.createServer((req, res) => {
res.end('hello')
}).listen(Math.round(1+Math.random()*1000))
通过fork方法复制的进程都是独立的进程,这个进程中有着独立的v8实例。他需要至少30ms的启动时间和至少10MB内存。
const cp = require('child_process')
cp.spawn('node', ['worker.js'])
cp.exec('node worker.js', function(err, srdout, stderr) {})
cp.execFile('worker.js', function(err, srdout, stderr) {})
cp.fork('./worker.js') // 只能执行Node脚本
后面三种都是spawn的延伸应用
父进程与子进程通讯将会创建IPC通道,他们可以通过message和send传递消息
// parent
const cp = require('child_process')
const n = cp.fork(_dirname + '/sub.js')
n.on('message', (m) => {
console.log(m)
})
n.send({hello: 'world'})
// sub
process.on('message', (m) => {
console.log(m)
})
process.send({foo: 'bar'})
Node通过管道实现的IPC通道,具体的实现由libuv提供。父进程再创建子进程前,会创建IPC通道监听它,然后创建。并通过环境变量(NODE_CHANNEL_FD)告诉子进程这个IPC通道的文件描述符。子进程启动过程中,根据文件描述符连接这个已存在的IPC通道。IPC通道属于双向通信,他们在系统内核中就完成了进程通信,不用经过实际的网络层。
send方法除了可以发送数据以外,还可以发送句柄,第二个参数就是句柄。
句柄就是可以用来标示资源的引用,他的内部包含了指向对象的文件描述符。用句柄可以表示一个socket对象、UDP套接字、一个管道等
// parent
const cp = require("child_process")
const servcer = require("net").createServcer()
const child1 = ap.fork('child.js')
const child2 = ap.fork('child.js')
server.listen(8080, () => {
child1.send('server', server)
child2.send('server', server)
server.close()
})
// child
const http = require("http")
const server = http.createServer((req, res) => {
res.writeHead(200, {'content-type': 'text/plain'})
res.end('child' + process.pid)
})
process.on('message', (m, tcp) => {
if(m === 'server') {
tcp.on('connection', (socket) => {
server.emit('connection', socket)
})
}
})
在父进程中,创建两个子进程,将他的服务器句柄发送给子进程,然后将其关闭。子进程中,创建了http服务,在接受到tcp句柄后,手动触发了http连接。这样,实现了两个子进程同时监听8080端口的效果
sned方法可发送的对象包括
net.socket、net.server、net.native、dram.socket、dram.nativesend方法在将消息发送到IPC管道前,将消息组装成两个对象,一个handle,一个是message
// 组装后的message对象 { cmd: "NODE_HANDLE", type: "net.Server", msg: message }发送到IPC管道的实际是句柄文件描述符,它是一个整数值。message写入IPC管道时会进行序列话,所以最终发送到IPC通道中的信息都是字符串。子进程接受到后通过JSON.parse还原后,出发message事件把消息传递给应用层。
这个过程中,消息对象还会被过滤,如果cmd是NODE_为前缀的,他将响应一个内部事件internalMessage。如果是NODE_HEADLE,他将取出message.type值和得到的文件描述符还原出一个对应的对象。
// 还原过程 const server = new net.Server() server.listen(handle, () => { // 监听到文件描述符上 emit(server) })当多个进程监听相同端口时实际会引起异常,因为当我们独立启动时,tcp服务器socket套接字的文件描述符并不相同,导致监听到相同端口时会抛出异常。node底层为每个端口设置了SO_REUSEADDR选项,他的含义是不同进程可以就相同网卡和端口进行监听,这个服务器套接字可以被不同进程复用。由于独立启动的进程互相之间不知道文件描述符,所以监听相同端口会抛出异常。多个应用监听同一个端口的时候,文件描述符一时间只能被某个进程所用,所以网络请求出现时,只有一个进程可以抢到连接。
# 创建稳定集群
上面我们创建多进程,但它并不稳定,需要加入一些细节
- 自动重启
- 负载均衡
node默认提供的极致采用操作系统的抢占式策略,就是在一堆工作进程中,闲着的进程对来到的请求进行争抢。而Node的繁忙是由CPU、I/O两部分构成的,影响抢占的是CPU的繁忙度,对不同业务,可能存在I/O繁忙,cpu空闲的情况,这可能造成某个进程能抢到较多请求,形成负载不均衡
node提供了一种Round-Robin策略,即轮叫调度。他的工作方式是主进程接受连接,依次分发给工作进程。分发策略是在N个工作进程中,没错选择第i = (i+1)mod n个进程来发送链接。在cluster模块中启动它的方式如下
// 启用 cluster.schedulingPolicy.= cluster.SCHED_RR // 不启用 cluster.schedulingPolicy.= cluster.SCHED_NONERound-Robin策略可以避免cpu和I/O繁忙差异导致的负载不均衡
// master
const fork = require('child_process').fork
const cpus = require('os').cpus()
const server = require('net').createServer()
const limit = 10 // 重启次数,如果进程在启动过程中失败,或启动后接到连接就受到错误,会导致工作进程被频繁启动,这种无意义重启需要被限制
const during = 60000
const restart = []
const workers = {}
server.listen(8080)
const isTooFrequently = () => {
const time = Date.now()
const length = restart.push(time)
if(length > limit) {
restart = restart.slice(limit * -1)
}
return restart.length >= limit && restart[restart.length - 1] - restart[0] < during
}
const createWorker = runction() {
if(isTooFrequently()){// 是否重启过于频繁
// 触发giveup事件后,不再重启。giveup是比uncaughtException更严重的一场,他表示集群中没有任何进程服务了
process.emit('giveup', length, during)
return
}
const worker = fork(__dirname + 'worker.js')
// 接收到自杀信号后重建服务
worker.on('message', message => {
if(message.act === 'suicide') {
createWorker()
}
})
worker.on('exit', () => {
console.log(worker.pid + 'exit')
delete workers[worker.pid]
})
worker.send('server', server)
workers[worker.pid] = worker
console.log('Create worker pid:' + worker.pid)
}
for(let i = 0; i < cpus.length; i++) {
createWorker()
}
process.on('exit', () => {
for(let pid in workers) {
workers[pid].kill()
}
})
// worker
const http = require('http')
const server = http.createServer((req, res) => {
res.writeHead(200, {'content-type': 'text/plain'})
res.end('handle by child' + process.pid)
})
let worker
process.on('message', (m, tcp) => {
if(m === 'server') {
worker = tcp
worker.on('connection', (socket) => {
server.emit('connection', socket)
})
}
})
process.on('uncaughtException', err => {
// 记录日志
console.error(err)
// 向父进程发送自杀信号,准备断开
process.send({ act: 'suicide' })
// 停止接收新的连接
worker.close(() => {
// 所有已由连接断开后,退出程序
process.exit(1)
})
// 设置一个超时时间,指定时间后还没退出则强制退出
setTimeout(() => {
process.exit(1)
}, 5000)
})
# Cluster
cluster是node提供的创建node进程集群的工具。对于上面的代码可变为
// cluster
const cluster = require('cluster')
cluster.setupMaster({
exec: "worker.js"
})
const cpus = require('os').cpus()
for(let i = 0; i < cpus.length; i++) {
cluster.fork()
}
// 另一种写法
const cluster = require('cluster')
const http = require('http')
const numCPUs = require('os').cpus().length
if(cluster.isMaster) {
for(let i = 0; i < numCPUs; i++) {
cluster.fork()
}
cluster.on('exit', (worker, code, signal) => {
console.log('worker' + worker.process.pid + 'died')
})
} else {
http.createServer((req, res) => {
res.writeHead(200)
res.end("hello")
}).listen(8080)
}
cluster模块其实是child_process和net模块的组合应用。cluster启动时,他会在内部启动tcp服务,在cluster.fork子进程时,将这个tcp服务端socket的文件描述符发送给工作进程。如果进程是通过cluster.fork复制出来的,那么他环境变量中就存在NODE_UNIQUE_ID,如果工作进程中存在listen侦听网络端口的调用,他将拿到该文件描述符,通过SO_REUSEADDR端口重用,实现多个子进程共享端口。
在cluster内部隐式创建tcp服务器的方式对于使用者十分透明,但也使得他不如直接用child_process那样灵活。
# 第三方包
# nodemon 热更新
安装开发依赖
yarn add nodemon -D # 加-D是指在开发环境中安装。
配置开发命令
"scripts":{
"start":"nodemon bin/www"
}
如果nodemon后面没有参数,那么他将自动读取package中的main文件。
{ "main": "bin/www", "scripts": { "start": "nodemon", }, }
配置监听文件nodemon.json
{
"watch": [ // 监听的目录
"./src/**/*.*"
],
"restartable": "rs",
"ignore": [
".git",
"node_modules/**/node_modules"
],
"verbose": true, // 输出信息
"execMap": { // "js": "node --harmony" 表示用 nodemon 代替 node --harmony 运行 js 后缀文件;
"": "node",
"js": "node --harmony"
},
"events": { // 触发事件后执行
"restart": "node test.js"
},
"env": {
"NODE_ENV": "development",
"PORT": "3000"
},
"ext": "js json" // 监控文件类型
}
时间包括
events:这个字段表示 nodemon 运行到某些状态时的一些触发事件,总共有五个状态:
- start - 子进程(即监控的应用)启动
- crash - 子进程崩溃,不会触发 exit
- exit - 子进程完全退出,不是非正常的崩溃
- restart - 子进程重启
- config:update - nodemon 的 config 文件改变
该
node --harmony标志允许您使用标记为staged 的ECMAScript 6 (ES6) 功能。暂存功能是尚未被视为稳定的已完成功能,并且在达到发货状态时可能会发生重大更改。
您可以从NodeJS 文档页面 中 (opens new window)找到更多信息。
今天,最新的 NodeJS 版本已经支持 ES6 特性,所以不再需要这个
--harmony标志。如果您发现您的应用程序在没有
--harmony标志的情况下无法运行,您可能需要将您的 NodeJS 版本更新到最新的稳定版本。
# koa-body
之前使用 koa2 的时候,处理 post 请求使用的是 koa-bodyparser,同时如果是图片上传使用的是 koa-multer。
这两者的组合没什么问题,不过 koa-multer 和 koa-route(注意不是 koa-router) 存在不兼容的问题。
这个问题已经在这篇文章中说明了:
关于 koa-bodyparser 的使用,见下面文章:
但是这两者可以通过 koa-body 代替,并且只是用 koa-body 即可。
# Magic-string
是一个操作字符串和生成source-map的工具
var MagicString = require('magic-string');
var magicString = new MagicString('export var name = "beijing"');
//类似于截取字符串
console.log(magicString.snip(0,6).toString()); // export
//从开始到结束删除字符串(索引永远是基于原始的字符串,而非改变后的)
console.log(magicString.remove(0,7).toString()); // var name = "beijing"
//很多模块,把它们打包在一个文件里,需要把很多文件的源代码合并在一起
let bundleString = new MagicString.Bundle();
bundleString.addSource({
content:'var a = 1;',
separator:'\n'
});
bundleString.addSource({
content:'var b = 2;',
separator:'\n'
});
/* let str = '';
str += 'var a = 1;\n'
str += 'var b = 2;\n'
console.log(str); */
console.log(bundleString.toString());
// var a = 1;
// var b = 2;
# invariant
当 invariant 判别条件为 false 时,会将 invariant 的信息作为错误抛出
var invariant = require('invariant');
invariant(
2 + 2 === 4,
'You shall not pass!'
);